《Multimodal Image Synthesis and Editing: A Survey》
Fangneng Zhan, Yingchen Yu, Rongliang Wu, Jiahui Zhang, Shijian Lu§
-
FOUNDATIONS
-
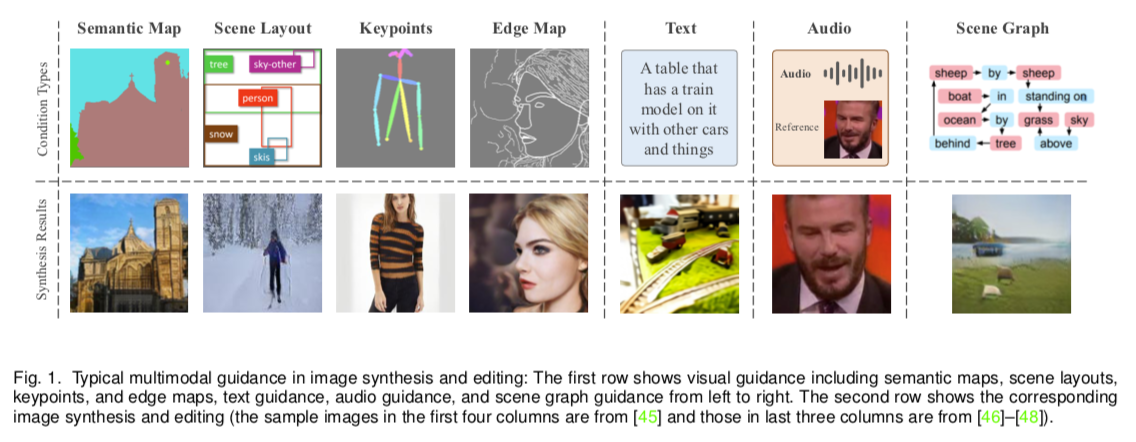
Visual Guidance
visual guidance represents certain image properties in pixel space
-
Text Guidance
text prompt provides a more flexible way to express visual concepts
Text Encoding:Word2Vec、 Bag-of-Words、 char-CNN-RNN、 LSTM、 StackGAN、 CLIP…
-
Audio Guidance
Sounds can not only interact with visual contents but also capture rich semantic information(e.g.,SoundNet can learn to identify scenes and objects by using auditory contents only)
-
Other Modality Guidance
generate images from scene graphs which define the explicit relationship among objects.
-
-
METHODS
-
GAN-based
-
GAN-inversion
-
Transformer-based
-
other
-
GAN-based Methods
-
Paired Visual Guidance:the provided guidance is accompanied with corresponding ground truth images to provide certain direct supervision.(e.g., cGAN, )
-
Unpaired Visual Guidance:Unpaired image synthesis utilizes unpaired training images to convert images from one domain to another.
-
Stacked Architectures:Targeting to synthesize high- resolution images(e.g., StackGAN generates a coarse image of 64×64 at the first stage, followed by a second generator to further output an image of 256 × 256 at the second stage)
-
Attention Mechanisms:allow the model to focus on specific part of an input, attention mechanisms have proven to be beneficial to language and vision models (e.g., AttnGAN, SEGAN, ControlGAN)]
-
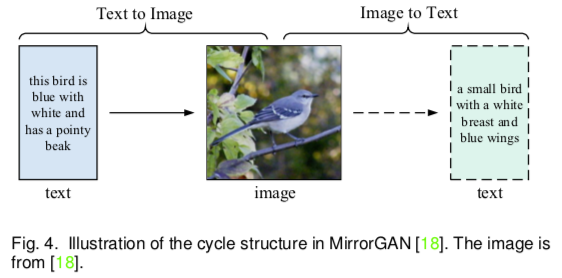
Cycle Consistency:
-
Adapting Unconditional Models:text-to-image generation(e.g., textStyleGAN extends StyleGAN, BigGAN, TVBi-GAN…)
-
-
GAN Inversion Methods
-
Preliminary:To bridge real and fake image domains, a series of studies aim to invert a given image back into the latent space of a pre-trained GAN model, which is termed as GAN inversion
-
Cross-modal Matching in Latent Space:(e.g., TediGAN proposes to achieve multimodal image syn- thesis & editing by matching the embeddings of images and cross-modal input in a common embedding space)
-
Image Code Optimization in Latent Space:aims to optimize the latent code of the original image directly, guided by certain loss that measures cross-modal consistency.(e.g., pushes the output latent code to change in a direction consistent with the text description, StyleCLIP)
-
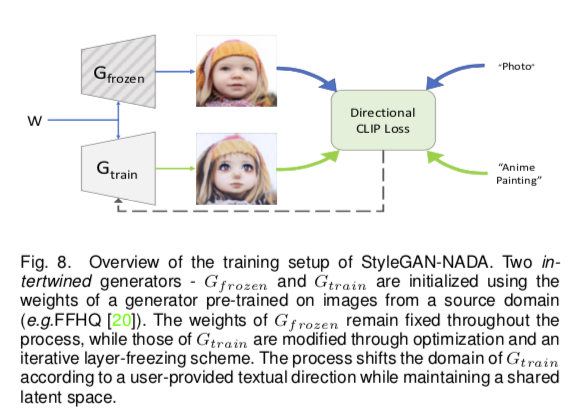
Domain Generalization:StyleCLIP requires to train a separate mapper for each specific text description which is not flexible in real applications. (e.g., HairCLIP: a hair editing framework that supports different texts by exploring the potential of CLIP to go beyond measuring image text similarity. StyleGAN- NADAL:presents a text-guided image editing method that allows to shift a generative model to new domains without having to collect even a single image)
-
-
Transformer-based Methods(不熟)
-
Transformer Preliminary:As Transformer models inherently support multimodal inputs, a series of studies have been proposed to explore multimodal image synthesis based on Transformer
-
Discrete Vector Representation:Directly treating all image pixels as a sequence for auto- regressive modeling is expensive in terms of memory con- sumption as the self-attention mechanism in Transformer incurs quadratic memory cost.
VQ-VAE:quantize image patches into discrete tokens with a learnt vector codebook. consists of an encoder, a feature quantizer, and a decoder.
Transformer Architecture:
-
Auto-regressive Modeling:Autoregresssive model has been widely explored for building sequence dependency
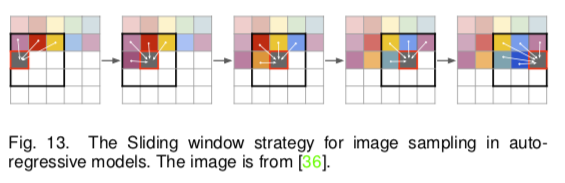
Sliding Window Sampling:
Bidirectional Context:
3D Nearby Self-Attention:not only deal with videos as 3D data but also adapt to texts and images as 1D and 2D data, respectively.$ Y = 3DNA(X, C; W)$ $ X$ and $C$ both are 3D representations
-
-
Other Methods
- Neural Radiance Fields(NeRF):NeRF achieves impressive performance for novel views synthesis by using neural network to define an implicit scene representation
- Diffusion Models
- Style Transfer:CLIPstyler propose to achieve text guided style transfer by training a lightweight network which transform a content image to follow the text condition by matching the similarity between the CLIP model output.
-
-
CHALLANGES
- Towards Integrating All Modalities(像人一样综合多模态的信息(e.g., 视觉,文本,声音)):Targeting to mimic the human intelligence, the generation models are expected to be able to handle guidance from multiple modalities concurrently. To achieve that, a comprehensive dataset which is equipped with anno- tations from all modalities needs to be created.
- Evaluation Metrics: Designing accurate yet faithful evaluation metrics is thus very meaningful and critical to development of multimodal image synthesis and editing.
- Model Architecture:design an architecture with natural support for multimodal inputs and fast inference speed remains a grand challenge to explore.